1Department of Audiology and Speech-Language Pathology, Hallym University of Graduate Studies, Seoul, Korea
2Department of Otorhinolaryngology-Head and Neck Surgery, Kyung Hee University Hospital at Gangdong, Seoul, Korea
3Ear to Brain, Incheon, Korea
4Kim Sung-Gun Hearing Clinic, Seoul, Korea
5HUGS Center for Hearing and Speech Research, Seoul, Korea
Correspondence: Jae Hee Lee, PhD Department of Audiology and Speech-Language Pathology, Hallym University of Graduate Studies, 427 Yeoksam-ro, Gangnam-gu, Seoul 06197, Korea Tel: +82-2-2051-4952 Fax: +82-2-3451-6618 E-mail: leejaehee@hallym.ac.kr
Received July 4, 2024 Revised July 12, 2024 Accepted July 12, 2024
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
Purpose
Clinical speech recognition measures often present the sentences recorded with a single speaker and one rate of speech. Performances with single-talker recordings may not accurately represent the speech recognition abilities of the listeners in a multitalker communication situation. The present study aimed to construct and optimize the sentences recorded by 20 different talkers for sentence-in-noise recognition tests (20-talker Korean sentence-in-noise test, 20-talker K-SIN).
Methods
Phases I and II were conducted in this study. In phase I (developmental phase), preliminary 720 sentences composed of 3 to 6 words were selected and recorded by twenty different talkers (10 male and 10 female). The recorded sentences were superimposed to generate a speech-shaped noise similar to the long-term average speech spectrum of the sentences. In phase II (optimization and formation of equally intelligible sentence lists), the psychometric functions of 30 normal-hearing listeners were obtained from the sentence-in-noise recognition scores at three different signal-to-noise ratios (SNRs) (-2, -4, and -7 dB). Based on these scores, the SNR required for 50% sentence intelligibility (SNR-50) and the slope at that point were derived from the psychometric function curves.
Results
Before level adjustment, the median SNR-50 and slope were -4.12 dB SNR and 24.33%/dB over 720 sentences. Level adjustments were applied to homogenize the intelligibility of the sentences, resulting in 508 sentences remained. Out of 508 sentences, 320 sentences were used to construct 1 practice list and 15 test lists, wherein 20 sentences in each list were spoken by each of the 20 different talkers.
Conclusion
The 20-talker K-SIN sentences can be used for high-variability speech-in-noise recognition test to better reflect the multitalker communication abilities of listeners.
청능사(audiologist)는 표준청력검사 절차(standard audiological test battery) 중 하나로 어음인지검사(speech recognition test)를 시행하여 난청인의 어음인지 및 의사소통 능력을 평가하고 청각재활을 계획하는 데 활용한다(Killion et al., 2004; Mackersie, 2002). 어음인지검사 절차로 조용한 상황 혹은 소음 상황에서 단음절어, 문장 등을 목표 어음으로 제시하여 청자의 단음절인지도(word recognition score), 문장인지도(sentence recognition score, SRS), 소음하 문장인지도(sentence recognition score in noise, SRS in noise) 등을 구하게 된다(Lee & Yi, 2017; Vermeire et al., 2003).
위에 나열한 검사 도구 대부분이 한 명의 화자(single talker)가 일정한 말 속도로 녹음한 어음을 목표 문장으로 제시한다. 이와 같이 단일화자가 문장을 반복해서 제시할 경우 청자가 화자의 음성에 친숙해지는 등 어음인지 처리 과정에서 중요하게 여기는 화자 변수(talker variability) 영향이 감소될 수 있다(Mullennix et al., 1989; Sommers, 1997; Sommers & Barcroft, 2006). 건청인의 경우 다양한 화자가 서로 다른 발화 속도, 발화 스타일, 악센트 등을 가지고 있어도 화자의 음성 내 일정한 음운(phonological) 및 의미(semantic) 정보를 안정적으로 처리하여 의미를 추출할 수 있는 적절한 지각 정규화(perceptual normalization) 능력을 보인다(Johnson & Mullennix, 1997; Pisoni, 1993; Sommers et al., 1994). 이와 달리 난청인의 경우 서로 다른 화자의 음성을 인식할 때 음성 내 다양한 음향-음성(acoustic-phonetic) 정보를 처리하는 능력이 떨어져 어음인지 저하를 유발할 수 있다(Kirk et al., 1997; Sommers et al., 1997). 따라서 단일화자가 녹음한 문장인지검사 결과는 화자 변수의 영향을 반영하지 못하는 제한점을 가진다.
위의 제한점을 고려하여 다양한 연구자들이 다수의 화자가 녹음한 어음인지검사 도구를 개발하였다. 예를 들어 AzBio 문장인지검사 도구의 경우 4명의 화자(남성 2명, 여성 2명)가 문장을 녹음하여 특정 목표 화자의 음성에 익숙해지는 효과를 줄이려고 노력하였다(Spahr & Dorman, 2004; Spahr et al., 2012). AzBio 검사는 15개의 문장 목록(목록당 20개 문장), 총 300개 문장을 포함하고 있으며, 목록당 133~154개의 중심 단어에 대한 정반응률을 통해 SRS를 도출한다. 2013년에 발표된 perceptually robust English sentence test (PRESTO; Gilbert et al., 2013)의 경우 18명(남성 9명, 여성 9명)의 서로 다른 지역 악센트를 가진 화자가 번갈아가며 목록 내 18개 문장을 발화하게 구성하여, 화자 변수를 최대한 반영하고자 하였다. 오스트레일리아 영어 버전으로 만들어진 Matrix 문장인지 검사의 경우 7명의 전문 성우와 3명의 일반인, 총 10명의 화자(남성 5명, 여성 5명)가 Matrix 문장을 녹음하여 multi-talker Australian matrix sentence test를 개발하였다(Kelly et al., 2017). 그 외 서로 다른 지역(New England, Northern, North Midland, and Western 등)의 악센트를 가진 630명의 화자가 녹음한 영어 Texas Instruments/Massachusetts Institute of Technology (TIMIT) 말뭉치(Garofolo et al., 1993), 서로 다른 8명 화자가 녹음한 256개의 coordinate response measure (Bolia et al., 2000) 문장(총 2,048개 문장) 등이 어음인지 연구에 활발히 사용되고 있다(Best et al., 2016; Eddins & Liu, 2012).
Gilbert et al.(2013)은 0, 3 dB signal-to-noise ratio (SNR) 듣기 조건에서 단화자가 발화한 HINT 문장에 비해 18명의 화자가 번갈아가며 발화하는 PRESTO 문장을 제시하였을 때 저하된 SRS in noise를 보였음을 보고하였다. 이는 목표 문장의 강도가 소음 강도와 같거나 더 큰 환경에서 청자는 서로 다른 발화 특성을 가진 화자의 음성에 내제되어 있는 음향학적, 언어적, 개별 지표적 특성(indexical feature)의 영향을 받음을 의미한다. 실제로 PRESTO, TIMIT, multi-talker Australian matrix sentence test 등 모두 최소 10명 이상의 다화자가 목표 화자로 문장을 발화하여 화자 변수를 최대화하면서도, 검사 도구로서 우수한 신뢰도와 타당도를 가짐을 보였다(Gilbert et al., 2013; Kelly et al., 2017; King et al., 2012).
난청인의 경우 청능평가 및 재활효과 검증을 위해 반복적으로 어음인지검사를 받게 되는 경우가 많으므로 국내에도 화자의 친숙화(talker familiarity) 효과를 감소시키고 화자 변수를 증가할 수 있는 다수의 화자가 녹음한 소음하 문장인지검사 도구 개발이 필요하다. 본 연구에서는 20명의 서로 다른 화자가 번갈아가며 한 문장씩 발화하는(목록 내 총 20개 문장) 한국어 소음하 문장인지검사(20-talker Korean sentence-in-noise test, 20-talker K-SIN) 문장 목록을 개발하고자 하였다. 아래의 두 단계를 거쳐 본 연구를 진행하였다. 1단계(developmental phase)에서는 남성 10명과 여성 10명, 총 20명 화자를 통해 1차 선정된 720개 문장을 녹음하고, 해당 문장과 유사한 스펙트럼을 보이는 어음스펙트럼 소음을 제작하였다. 2단계(optimization and formation of equally intelligible sentence lists)에서는 건청인 30명에게 녹음한 문장을 제시하여 심리음향기능곡선(psychometric function) 분석 및 최적화 후 최종 20-talker K-SIN 문장 목록을 구성하였다.
MATERIALS AND METHODS
Phase 1: developmental phase
1단계에서는 20-talker K-SIN 목록에 포함할 문장 720개를 1차 선정하였다. 전문 성우 혹은 일반인 화자로 구성된 20명의 화자(남성 10명, 여성 10명)를 선정한 후 각 화자별로 720개 문장을 발화하게 하여 총 14,400개의 문장 음원을 녹음 및 편집하였다. 녹음된 문장들의 장기평균어음스펙트럼을 가진 어음스펙트럼 소음을 제작하여 검사 도구의 배경소음으로 사용하고자 하였다.
예비 문장 발췌 시 문장 내 어휘 및 주제, 문장 구조 선정 기준은 다음과 같았다. 먼저 문장 내 어휘 및 주제를 선택 시, ① 일상생활에서 친숙하게 사용되는 주제(예시: 가족, 날씨, 음식, 건강, 교통 등)를 포함하고, ② 일상생활에서 자주 사용되는 고빈도 외래어와 고유명사는 일부 포함하며(예시: 마트, 카페, 서울, 제주도, 한국 등), ③ 성, 종교, 정치, 전쟁과 관련된 의미를 내포하는 어휘는 제외하고, ④ 문장 내 어휘의 음소빈도 분포가 한국어 사용빈도 분포와 유사하도록 구성하였다. 문장 구조 면에서는 다음과 같이 문장을 선택하였다. ① 단문 혹은 복문을 포함하는 문법 구조를 가지며, 쉽게 이해 가능한 생활 회화체 문장을 포함하였고, ② 평서문, 의문문, 명령문 등 다양한 문장 형태를 가지며, ③ 청자의 단기기억 능력에 의한 영향을 최소화하기 위해 3~6어절의 문장으로 구성하였고(2어절 이하 문장은 난이도가 쉽고, 7어절 이상 문장은 단기기억의 영향을 받을 수 있어 제외함), ④ 문장 내용이 아동이 아닌 성인에게 적절하도록 하였다.
청각언어재활 전문가 5인(청각학 전공 교수, 전문청능사, 청능사, 언어재활사 등)이 위에서 추출한 예비 문장 1,260개 중 문법에 맞지 않거나 맞춤법 및 의미 수정이 필요한 문장을 확인하였다. 국립국어원 우리말샘(https://opendict.korean.go.kr/main)과 국문학 전문가의 자문 의견을 참고하여 문장 내 단어를 첨가하거나 변경하는 수정 과정을 거치거나 기준에 안 맞는 문장을 아예 제외하였다.
다음은 문장을 제외한 기준 혹은 수정 예시를 보여준다. ① 부정적인 느낌이 들 수 있는 문장 제외(예시: 칼은 위험한 도구이다), ② 문장 의미의 모호성을 줄이기 위해 지시 대명사 ‘이’, ‘그’, ‘저’, ‘여기’, ‘그거’ 등을 다른 단어로 대체(대체 예시: 그 영화가 곧 개봉한다→기다리던 영화가 곧 개봉한다), ③ 행위의 주체 및 목적 대상을 명확히 하기 위해 경우에 따라 주어 혹은 목적어를 첨가(수정 예시: 나보다 두 살 많다→형은 나보다 두 살 많다), ④ 어절 수 조절을 위해 경우에 따라 문장 내 조사 혹은 부사를 첨가(수정 예시: 주변에 공사장이 있어서 시끄럽다→주변에 공사장이 있어서 매우 시끄럽다), ⑤ 종결 어미를 수정하여 평서문, 의문문, 명령문 다양한 문장 형태를 포함하였다.
다음 단계로 위 청각언어재활 전문가 5인이 문장에 대한 자연성(naturalness) 정도를 5점 척도로 평가하여(1점: 매우 부자연스럽다~5점: 매우 자연스럽다) “1점: 매우 부자연스럽다” 혹은 “2점: 부자연스럽다”에 해당하는 문장을 제외하였다. 위 과정을 통해 720개 문장을 20-talker K-SIN 문장으로 1차 선정하였다.
Recording and editing of sentences
본 연구의 목표는 화자 변수를 최대화한 20-talker K-SIN 문장 목록을 구성하는 것이었다. 각 목록 내 20개의 문장을 서로 다른 화자가 발화하게 하기 위해 남녀 성별이 균등하게 20명의 화자를 선정하고자 하였다. 20-talker K-SIN 문장 발화에 참여할 화자 모집을 위해 성우로 활동하는 사람들이 가입한 온라인 커뮤니티, 일반 구직 사이트 등에 연구 참여자 모집 정보를 제공하여 지원자를 모집하였다. 전문청능사, 청능사, 언어재활사가 총 150명의 지원자가 보내준 샘플 녹음 화일을 모두 들어본 후 아래의 다섯 가지 기준에 맞는 화자 20명(남성 10명, 여성 10명)을 20-talker K-SIN 화자로 선정하였다(① 표준어 사용, ② 낭독 속도와 호흡이 안정적, ③ 발음 및 조음이 정확, ④ 목소리가 갈라지거나 째짐 없음, ⑤ 발화 스타일이 자연스러워 듣기 거부감 없는 화자).
화자 20명의 평균 연령은 29.5세(range, 19~48세)였고, 본 연구에 참여한 20명의 화자는 현재 전문 성우로 활동하고 있는 사람, 훈련 중인 성우 지망생, 신문방송학 전공자로 과거에 방송 경험이 있는 사람, 음성치료사, 일반인 등 다양하게 구성하였다. 모든 화자는 만성적 혹은 일시적 음성 문제를 가지고 있지 않았고, 대상자 모두 연구 목적과 녹음 진행 과정에 대한 설명을 듣고 연구 동의서에 서명 후 녹음에 참여하였으며 연구 참여에 대한 보상을 받았다.
문장 녹음은 국제표준화기구(International Organization for Standardization, ISO)에서 권고하는 소음허용수준(International Organization for Standardization, 2012)을 만족하는 3.4 × 5.8 × 2.22 m (가로 × 세로 × 높이) 규격의 방음실에서 실시하였다. 녹음에 사용된 장비는 AKG C414 XLS (Akustische und Kino-Geräte Gesellschaft m.b.H, Vienna, Austria) 컨덴서 마이크로폰, Focusrite clarett 8pre (Focusrite Audio Engineering Ltd, High Wycombe, UK) A/D Converter, SONY MDR-7506 (Sony Corporation, Tokyo, Japan) 헤드폰, NT900X3G (Samsung, Seoul, South Korea) 노트북이었다.
각 화자는 실제 녹음 전 자연스럽게 발화할 수 있도록 낭독할 문장을 통해 미리 연습 시간을 가졌다. 충분한 연습이 끝난 후 1차 선정한 문장 720개를 모두 낭독하였고, 발화 시 보통 말소리 크기 및 발화 속도를 유지할 것을 요청하였다. 녹음 시 마이크와 화자의 입 간 거리는 20 cm로 일정하게 유지하도록 하였다. 다수의 문장을 읽어야 하였으므로 화자의 목 피로 상태를 고려하여 녹음 중간에 충분한 휴식을 취하면서 녹음을 진행하였다. 휴식 시간을 포함하여 총 720개의 문장을 1차 녹음하는 데 소요된 시간은 약 100~120분이었다. 문장 내 특정 단어의 발음이 정확하지 않았거나 부분적으로 말을 더듬은 문장은 1차 녹음이 끝난 후 재녹음하였다.
녹음한 문장은 WAV 포맷으로 각각의 파일로 저장하였으며(48 kHz sampling rate, 24-bit resolution), 20명의 화자 각각이 녹음한 720개의 문장, 총 14,400개의 문장 음원은 Adobe Audition CC (Adobe System Inc, San Jose, CA, USA) 소프트웨어를 사용하여 각 문장 음원의 실효값(root mean square)이 일치하도록 조정하였다. 녹음된 14,400개의 문장 음원의 발화 속도를 분석한 결과 남성 화자 10명이 발화한 속도는 초당 평균 6음절(standard deviation [SD], 0.42)이었다. 여성 화자 10명의 발화 속도는 초당 평균 5.71음절(SD, 0.40), 남녀 화자 20명의 발화 속도는 대략 초당 5.86음절이었다(SD, 0.41; range, 4.91~6.66). 이는 Shim(2005)이 보고한 화자의 평균 발화 속도(초당 대략 5.7 음절)와 유사하였다.
Generation of speech-shaped noise
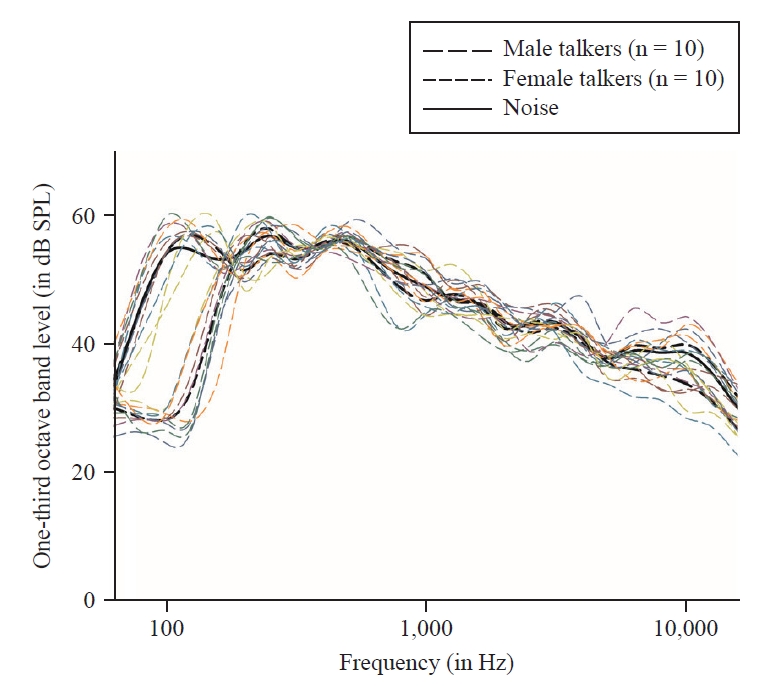
본 연구에서 녹음한 문장 음원을 30번씩 중첩(superimpose)하여 문장의 장기평균어음스펙트럼(long-term average speech spectrum, LTASS)과 유사한 어음스펙트럼 소음을 직접 제작하였다. Figure 1은 20명의 화자 각각이 녹음한 녹음한 문장의 LTASS, 남녀 10명의 평균 LTASS, 소음의 LTASS를 보여준다. Figure 1를 통해 알 수 있듯이 남녀 화자의 기본 주파수를 제외한 나머지 주파수(대략 250~8,000 Hz)에서 문장 LTASS와 본 단계에서 제작한 소음의 LTASS가 유사함을 알 수 있다.
Phase 2: optimization and formation of equally intelligible sentence lists
2단계에서는 건청인 30명에게 20명 화자가 녹음한 문장을 제시하여 심리음향기능곡선을 구하였다. 문장 강도 조절 및 일부 문장 제외 후 최종적으로 20명의 화자가 한 문장씩 번갈아가며 발화하는 20-talker K-SIN 검사 목록 15개와 연습 목록 1개, 총 320개 문장(목록당 문장 20개)을 개발하였다.
Selection of signal-to-noise ratios to achieve SRS in noise of 20%, 50%, and 80%
대상자의 심리음향기능곡선을 구하려면 최소 20%, 80%에 해당하는 SRS in noise를 통해 50% 인지도를 보일 SNR과 기울기(slope)를 구할 수 있다. 본 연구에서는 20%, 50%, 80%의 SRS in noise를 보일 세 개의 SNR을 선정하기 위해 5명의 건청인을 대상으로 예비 실험을 진행하였다. 예비 실험에 참여한 5명(남성 3명, 여성 2명) 모두 한국어를 모국어로 하였으며, 평균 연령은 24세(range, 20~30세), 양이 순음청력검사역치가 250-8,000 Hz 이내 옥타브 단위 주파수에서 15 dB hearing level (HL) 이하였다. 선행 연구(Bhat et al., 2021; Jain et al., 2014; Tanniru et al., 2017)에서 20~80%의 SRS in noise를 보인 -1~-7 dB SNR에서 1 dB 간격으로 SRS in noise를 측정하였다.
예비 실험 결과 -1 dB SNR에서 평균 SRS in noise가 98%였고, -2 dB SNR에서 74%, -3 dB SNR에서 68.76%, -4 dB SNR에서 53%, -5 dB SNR에서 40.4%, -6 dB SNR에서 34%, -7 dB SNR에서 20.73%의 SRS in noise를 보였다. 따라서 건청인이 -2, -4, -7 dB SNR에서 순서대로 70~80%, 45~55%, 20~30%의 SRS in noise를 보일 것이라 예측하였고, 이를 기준으로 본 연구에서는 -2, -4, -7 dB SNR에서 문장을 제시하여 심리음향기능곡선을 확인하였다.
Sentece-specific psychometric function of speech intelligibility
한국어를 모국어로 하는 건청 성인 30명(남성 15명, 여성 15명)이 청자로 참여하였다. 대상자의 평균 연령은 25.86세(range, 19~31세)로 양이 순음청력검사역치가 250~8,000 Hz 이내 옥타브 단위 주파수에서 15 dB HL 이하였다. 대상자 모두 이학적 또는 신경학적 문제를 가지고 있지 않았으며, 모든 참여 자는 연구 목적과 검사 절차에 대한 설명을 듣고 연구 동의서에 서명했으며 연구 참여에 대해 보상을 받았다.
위 1단계에서 선정한 문장을 -2, -4, -7 dB SNR에서 제시하였고, SNR 제시 순서는 무작위로 선택하였다. 검사 시 소음은 항상 65 dB sound pressure level에서 제시하였고, 대상자는 소음하 상황에서 각 문장을 듣고 따라 말하였다. 대상자 양이 모두 건청이었으므로 대상자가 듣기 선호하는 귀, 선호하는 귀가 없을 경우 우측 귀에 문장 음원을 제시하였다. 문장 제시에 사용한 기기는 청력검사기 GSI-61 pro star (Grason-Stadler, Madison, WI, USA), 헤드폰 TDH-39P (Telephonics, Huntington, NY, USA), Fireface UCX (RME, Haimhausen, Germany) D/A converter, 노트북 LG15U34 (LG, Seoul, South Korea)였다. 검사 도중 발생할 수 있는 대상자의 피로도를 고려하여 중간에 휴식 시간을 가졌다.
평가 시 검사자가 정확하게 오류를 분석하였는지 확인하기 위해 연구 대상자의 반응을 녹음하여 제2검사자와 함께 2차 분석하였다. 분석 시 문장 내 정반응한 중심 단어 개수를 기준으로 SRS in noise를 백분율로 점수화하였다. 채점 시 문장 내 조사는 중심 단어에 포함시키지 않았으나 문장 내 종결어미가 맞아야 정반응으로 간주하였다(예시: ‘먹는다’를 ‘먹다’, ‘먹습니다’, ‘먹네’ 등으로 말하면 오반응으로 간주함).
Optimization and level adjustment for equalization
-2, -4, -7 dB SNR에서 문장을 제시하여 SRS in noise를 측정한 후, 심리음향기능곡선을 통해 50%의 SRS in noise를 보이는 SNR(이하 SNR-50이라 지칭)과 그 지점에서의 기울기를 구하였다. 각 문장 음원의 SNR-50을 전체 음원의 SNR-50의 중앙값(median)과 최대한 일치시키기 위하여 SNR-50 차이값을 통해 문장들의 강도를 조절(level adjustment)하였다. 이 때, 강도 조절은 최대 ± 4 dB 이내로 제한하였고, 그 이상의 차이를 보이는 문장은 삭제하였다.
위 과정에서 1) 강도 조절을 하였음에도 각 문장 음원의 SNR50이 전체 문장의 SNR-50 중앙값과 2 dB 이상의 차이를 보이는 경우, 2) SNR-50을 접점으로 하는 기울기가 0 또는 6 이하 또는 200%/dB 이상인 음원은 제외했다. 위의 기준을 적용한 결과 720개 문장 음원 중 212개의 문장 음원이 제외되어 508개의 문장이 문장 목록 구성에 사용 가능한 문장으로 남게 되었다. 이러한 최적화 과정을 거친 후 심리음향기능곡선은 최대한 균일하게 되고 문장 간 SNR-50 및 기울기 편차가 좁아지는 효과가 있었다.
RESULTS
아래 결과는 720개 문장 음원을 제시하고 구한 최적화 전 심리음향기능곡선과 최적화 과정 후 남은 508개의 문장 음원의 심리음향기능곡선을 보여준다. 508개의 문장 중 여러 기준에 부합하는 15개의 K-SIN 검사 목록과 1개의 연습 목록을 구성하였다(검사 문장 300개, 연습 문장 20개, 총 320개 문장).
Psychometric functions obtained before and after optimization
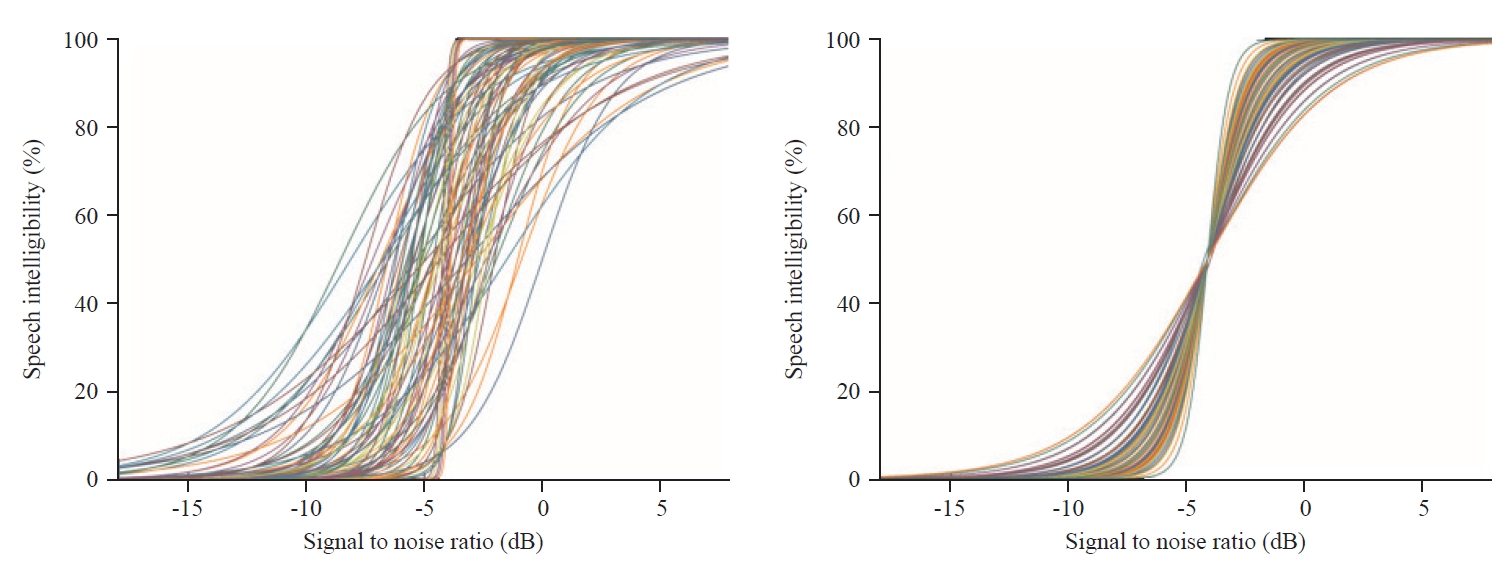
-2, -4, -7 dB SNR 순서대로 건청인의 평균 SRS in noise는 각각 74.72% (SD, 3.99), 54.93% (SD, 6.26), 20.74% (SD, 4.68)였다. 로지스틱 회귀분석을 이용하여 각 문장의 심리음향기능곡선을 구하였고, 이를 Figure 2 중 왼쪽 그림에 제시하였다. 최적화 전 SNR-50과 이를 접점으로 하는 기울기를 구한 결과, SNR-50의 중앙값은 -4.12 dB SNR, 평균값은 -3.84 dB SNR (SD, 9.21), SNR-50을 접점으로 하는 기울기의 중앙값은 24.33%/dB, 평균값은 66.71%/dB (SD, 87.05)였다.
문장의 강도를 조절한 후 508개 문장 음원의 심리음향기능곡선을 다시 구한 결과는 Figure 2 중 오른쪽 그림에 제시하였다. Figure 2를 통해 알 수 있듯이 최적화 전에 비해 최적화 후 각 문장 음원의 SNR-50이 전체 SNR-50의 중앙값과 최대한 일치되는 것을 확인할 수 있다. 최적화 후 SNR-50과 기울기를 다시 계산한 결과, SNR-50 중앙값은 -4.12 dB SNR, 평균값은 -4.15 dB SNR (SD, 0.21)였고, SNR-50을 접점으로 하는 기울기 중앙값은 24.09%/dB, 평균값은 40.42%/dB (SD, 47.67)였다.
Formation of equally intelligible 20-talker K-SIN lists
본 연구에서는 20명의 각 화자가 번갈아가면서 20개의 문장을 낭독하는, 즉 한 명의 화자가 하나의 문장씩 제시하도록 문장 목록을 구성하고자 하였다. 각 문장 목록에는 20개의 문장이 포함되게 하였으며, 각 목록 당 어절별 문장 수가 동일하도록 각 목록에 3어절 문장 5개, 4어절 문장 5개, 5어절 문장 5개, 6어절 문장 5개를 무작위 순서로 배열하였다. 문장의 의미, 문장 내 어휘, 어절 및 음절 수, 종결어미(‘-다’, ‘-까’, ‘-자’, ‘-요’, ‘-라’) 등이 다양하게 하였다. 다양한 문장 형태를 포함하기 위해 평서문 외에 최소 1개의 의문문을 목록 내에 포함하였다. 마지막으로, 각 문장의 SNR-50 접점 기울기가 75%/dB 이하인 문장만을 최종 목록에 포함시켰다.
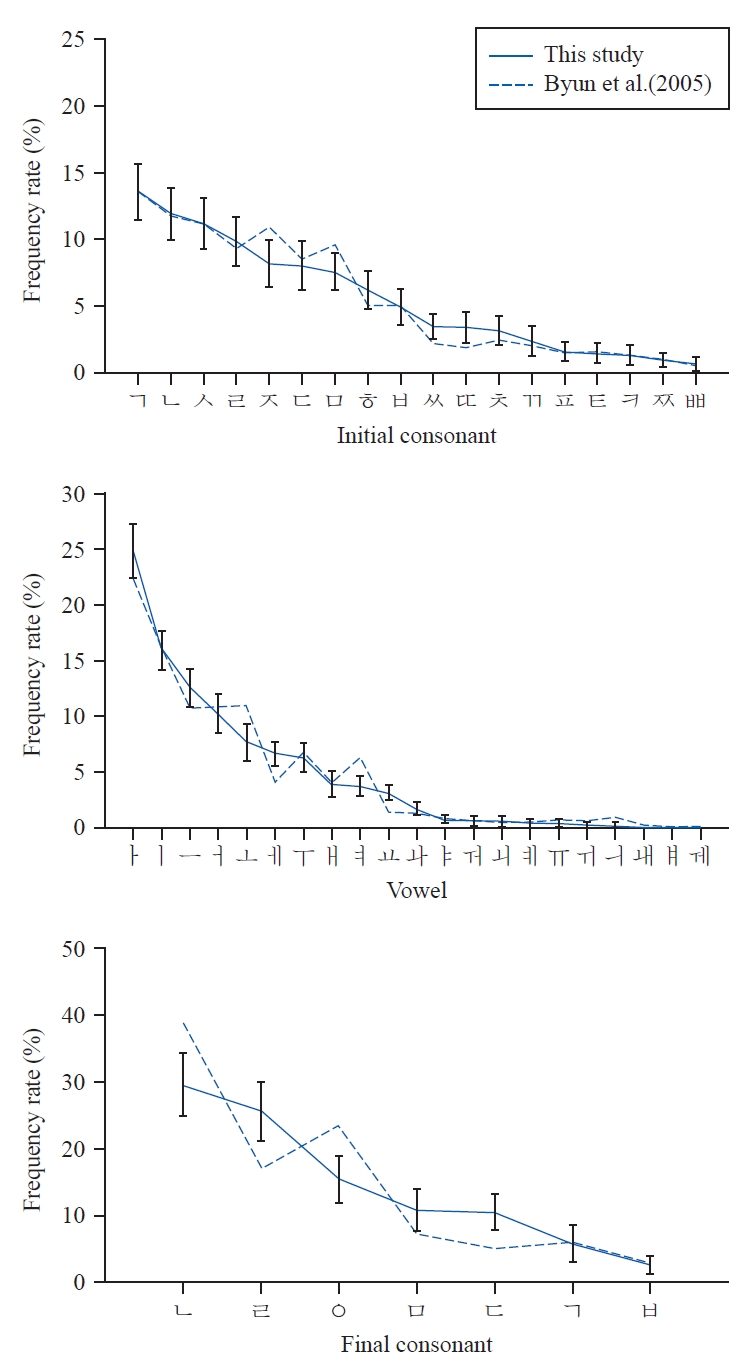
앞 단계에서 최적화 후 남겨진 508개 문장 중 위 조건을 모두 충족하는 1개의 연습 목록(문장 20개)과 15개의 검사 목록(문장 300개), 총 320개의 문장을 최종 20-talker K-SIN 문장으로 구성하였다(연습 목록과 검사 목록 모두 Appendix 1에 제시). 목록에 포함된 문장 내 음소별 빈도율을 분석하기 위해 언어재활사가 문장을 한국어 표준 발음법에 의거하여 전사하였다. 음소별 빈도 분포를 비교한 결과, 한국어 발음 음소별 빈도 기준(Byun et al., 2005)과 본 연구의 최종 문장 내 음소별 빈도가 대체로 유사하였다(Figure 3).
DISCUSSIONS
난청인은 주로 배경소음이 존재하는 상황에서 다수의 화자와 이야기할 때 의사소통의 어려움을 느낀다. 기존의 어음청각검사 도구는 주로 조용한 상황에서 단화자가 녹음한 단어 혹은 문장 음원을 이용하여 인지도를 측정하므로 이러한 검사 결과를 통해 배경소음 속 다화자 의사소통에서의 어려움을 예측하기 어렵다(Gilbert et al., 2013; Sommers et al., 1997). 특히 서로 다른 화자가 가지는 발화 특성이 난청인의 어음인지에 영향을 미치므로 이러한 화자 변수가 검사 도구 개발 시 반영되어야 한다(Mullennix et al., 1989; Sommers, 1997; Sommers et al., 1997; Sommers & Barcroft, 2006). Gilbert et al.(2013)은 18명의 화자가 녹음한 PRESTO 문장과 1명의 화자가 발화한 HINT 문장 결과와의 비교를 통해 단화자가 녹음한 소음하 문장인지검사의 제한점을 보고하였다. 0, 3 dB SNR에서 SRS in noise를 측정하였을 때 HINT 결과보다 PRESTO 결과가 유의하게 낮았으며, 그 이유는 여러 화자가 가지는 서로 다른 발화 속도, 악센트, 발화 스타일 등의 다양성이 청자의 소음하 어음인지에 영향을 미쳤을 것이라 분석하였다.
국내의 경우 위와 같은 다중화자 문장인지검사 도구 개발이 부족한 편이므로 본 연구에서는 20명 화자가 녹음한 문장을 건청인에게 제시하여 심리음향기능곡선을 분석하고 최적화를 시행하여, 20명의 서로 다른 화자가 번갈아가며 한문장씩 발화하는(목록 내 총 20개 문장) 20-talker K-SIN 검사 목록 15개(문장 300개)와 연습 목록 1개(문장 20개)를 구성하였다. 본 연구에서 개발한 20-talker K-SIN 문장 목록은 SRS in noise를 측정하기 위한 검사이므로 소음 없이 문장만 제시하는 검사 도구 개발과 절차가 달라야 한다. 소음하 문장인지검사 도구는 조용한 상황이 아닌 소음 상황에서 유사한 인지도(equal intelligibility)를 보이는지 확인하는 것이 중요하다. Bhat et al.(2021)은 Tulu 소음하 문장인지검사 개발 시 -8, -6, -4, -2 dB SNR에서 SRS in noise를 측정하였고, Jain et al.(2014)은 Hindi 소음하 문장인지검사 개발 시 -8, -6, -4, -2, 0 dB SNR에서 SRS in noise를 측정하여 20~80% 범위의 인지도를 확인하여 심리음향곡선을 구하였다. 이와 같이 다양한 dB SNR을 사용하는 이유는 20%, 50%, 80%에 해당하는 결과가 있어야 심리음향기능곡선을 통해 SNR-50과 기울기를 구할 수 있기 때문이다. 이를 위해 본 연구에서는 예비 실험을 통해 -2, -4, -7 dB SNR이 20%, 50%, 80%에 해당하는 dB SNR임을 확인하였고, 이 세 가지 dB SNR에서 소음하 문장인지도를 측정하여 50%의 소음하 문장인지도를 보이는 SNR-50과 이를 접점으로 하는 기울기를 구할 수 있었다.
본 연구에서는 문장의 강도를 조절하거나 제외시키는 최적화 과정을 거친 결과 최적화 전에 비해 최적화 후 SNR-50과 기울기의 편차가 감소하였다. 이와 같은 최적화 작업은 특히 소음하 문장인지검사 도구 개발 시 매우 중요하다. Yi(2016)의 경우에도 한국어 Matrix 문장인지검사를 위한 문장 개발 시 최적화 전에 비해 최적화 후 한국어 Matrix SNR-50 평균값과 기울기 모두 편차가 상당히 감소하였다. 이처럼 최적화 과정을 시행할 경우 SNR-50과 기울기 편차를 감소하고 문장 간 난이도를 최대한 균일화하여 검사 도구의 타당성을 높이는 장점을 가진다(Kim & Lee, 2018; Yi, 2016).
본 연구에서 20명의 서로 다른 화자가 녹음한 20-talker K-SIN 문장을 건청 성인에게 제시한 결과, 최적화 후 SNR-50 평균값은 -4.15 dB SNR이었다. 18명의 서로 다른 화자가 녹음한 PRESTO 문장을 건청 성인 40명에게 제시한 결과 -3 dB SNR에서 SRS in noise가 55%였으며, -5 dB SNR에서 약 38%의 SRS in noise를 보였으므로 약 -4 dB SNR에서 45~50%의 SRS in noise를 보였다는 점이 유사하였다. Tulu 소음하 문장인지검사를 개발 시(Bhat et al., 2021) 건청 성인이 -4.19 dB SNR에서 평균 50%의 SRS in noise를 보였으며, Hindi 소음하 문장인지검사를 개발 시(Jain et al., 2014) -4.20 dB SNR에서 평균 50%의 SRS in noise를 보였다. 이와 같은 유사한 결과가 보인 이유는 Bhat et al.(2021), Jain et al.(2014) 모두 개발 시 문장 선택 기준으로 정치, 성차별, 전쟁과 같은 주제에 해당하는 문장을 제외하였고, 일상생활에서 자주 사용되는 3~7어절 문장으로 선택하였으며, 각 문장의 자연스러움 정도를 사전에 평가했다는 점에서 본 연구와 유사하다. 단어인지검사 도구와는 다르게 문장인지검사 도구의 경우 목록 간 음소 균형에 초점을 맞추기보다는 문장 자체의 자연스러움, 다양한 문장 형태 포함, 과한 아나운서 스타일의 어조를 가진 화자보다 일반인이 듣기 자연스러운 어조를 가진 화자 선택 등 일상적인 대화 상황을 반영하려는 노력이 필요하였다.
본 연구는 다음과 같은 한계점을 가지고 있다. 첫째, 최적화 실험 시 20%, 50%, 80%의 인지도를 보일 것이라고 예측되는 -7, -4, -2 dB SNR에서 실험을 진행하였는데 세 개의 SNR만으로 심리음향기능곡선을 구할 수 없는 문장이나 평균에서 편차가 많이 벗어나는 문장이 다수 있었다. 이로 인해 최적화 과정에서 꽤 많은 수의 문장을 제외시켜야 했다. 최적화 실험을 한 국외 연구를 보면 Houben et al.(2014)은 5개의 SNR에서, Wagener et al.(2003)는 10개의 SNR에서 최적화 실험을 했다. Bhat et al. (2021)은 -8, -6, -4, -2 dB SNR에서, Jain et al.(2014)은 -8, -6, -4, -2, 0 dB SNR에서 SRS in noise를 측정하여 심리음향기능곡선을 구하였다. 본 연구에서도 5개 이상의 SNR에서 최적화 실험을 실시했다면 제외되는 문장의 수가 적어지거나 편차가 더 낮게 나왔을 것이다. 둘째, 본 연구에서는 20-talker K-SIN 검사 도구의 개발을 위하여 문장 선정 및 녹음 후 최적화를 진행하여 최종 문장 목록을 구성하였다. 후속 연구를 통해 건청인과 난청인을 대상으로 하여 검사-재검사 신뢰도 및 타당성 등을 측정하고, 목록 간 난이도 동질성을 검증하여야겠다. 셋째, 임상 현장에서 난청인을 대상으로 한가지 dB SNR을 이용하여 일상적인 소음하 어음인지검사를 진행하고자 한다면 실제 일상생활 속 dB SNR을 측정한 결과를 고려하여(Wu et al., 2018) 5 dB SNR에서 검사를 진행해 볼 수 있겠다. 본 연구에서는 성인을 대상으로 하는 도구를 개발하고자 하였으므로 이 도구를 학령전기 및 학령기 아동에게 시행하기 어렵다. 추후 연구에서 학령전기 및 학령기 아동용 다중화자 소음하 검사 개발이 이루어져야 겠다.
본 연구에서는 20명의 화자가 번갈아가며 목록 내 문장을 발화하는 한국어 소음하 문장인지검사(20-talker K-SIN) 목록을 개발 및 구성하였다. 최종 문장 목록으로 연습 목록 1개(문장 20개)와 검사 목록 15개(문장 300개)를 포함하였다(총 320개 문장). 타 도구와 다르게 20-talker K-SIN 검사 도구는 다수의 화자가 녹음한 어음을 목표 문장으로 제시하므로 화자의 음성에 내재된 음향학적, 언어적, 지표적 특성을 다양화하면서 청자의 소음하 문장인지능력을 측정할 수 있다는 장점을 가진다. 따라서 임상 현장에서 난청인의 다화자 의사소통능력 평가 시 20-talker K-SIN 검사를 활용할 수 있겠다.
Notes
Ethical Statement
This study was approved by the Institutional Review Board of Hallym University of Graduate Studies (#IRB: HUGSAUD624870).
Declaration of Conflicting Interests
There is no conflict of interests.
Funding
N/A
Author Contributions
Conceptualization: Seul Ah Lee, Dong-Woon Yi, Jae Hee Lee. Data collection: Seul Ah Lee, Dong-Woon Yi. Formal analysis: Seul Ah Lee, Dong-Woon Yi. Writing—original draft: Seul Ah Lee, Jae Hee Lee. Writing—review & editing: all authors. Approval of final manuscript: Jae Hee Lee.
Acknowledgments
N/A
Figure 1.
The long-term average spectra of the sentences recorded from 10 male and 10 female talkers (20 colored and dashed lines), the long-term average spectra averaged across male and female talkers (bold dashed lines), and noise spectrum (bold solid line). SPL: sound pressure level.
Figure 2.
Psychometric functions of speech intelligibility before (left) and after (right) optimization.
Akeroyd, M. A., Arlinger, S., Bentler, R. A., Boothroyd, A., Dillier, N., Dreschler, W. A., et al. (2015). International Collegium of Rehabilitative Audiology (ICRA) recommendations for the construction of multilingual speech tests: ICRA working group on multilingual speech tests. International Journal of Audiology, 54(Suppl 2), 17-22.
Best, V., Keidser, G., Freeston, K., & Buchholz, J. M. (2016). A dynamic speech comprehension test for assessing real-world listening ability. Journal of the American Academy of Audiology, 27(7), 515-526.
Bhat, S., Kalaiah, M. K., & Shastri, U. (2021). Development and validation of tulu sentence lists to test speech recognition threshold in noise. Journal of Indian Speech Language & Hearing Association, 35(2), 50-56.
Bolia, R. S., Nelson, W. T., Ericson, M. A., & Simpson, B. D. (2000). A speech corpus for multitalker communications research. The Journal of the Acoustical Society of America, 107(2), 1065-1066.
Boothroyd, A., Hanin, L., & Hnath, T. (1985, June 1). A Sentence Test of Speech Perception: Reliability, Set Equivalence, and Short Term Learning. Speech and Hearing Sciences Research Center, Retrieved from https://academicworks.cuny.edu/gc_pubs/399/.
Byun, S. W., Kim, J. K., Lee, S. S., & Bae, J. H. (2005). Excessive postobstruent tensing in Korean spondee word list: Comparison between the colloquial Korean language and hahm’s List. Korean Journal of Otolaryngology-Head and Neck Surgery, 48(5), 596-600.
Cox, R. M., Alexander, G. C., & Gilmore, C. (1987). Development of the connected speech test (CST). Ear and Hearing, 8(5), 119S-126S.
Eddins, D. A. & Liu, C. (2012). Psychometric properties of the coordinate response measure corpus with various types of background interference. The Journal of the Acoustical Society of America, 131(2), EL177-EL183.
Garofolo, J. S., Lamel, L. F., Fisher, W. M., Fiscus, J. G., & Pallett, D. S. (1993). The DARPA TIMIT Acoustic-phonetic Continuous Speech Corpus. Philadelphia, PA: Linguistic Data Consortium.
Gilbert, J. L., Tamati, T. N., & Pisoni, D. B. (2013). Development, reliability, and validity of PRESTO: A new high-variability sentence recognition test. Journal of the American Academy of Audiology, 24(1), 26-36.
Houben, R., Koopman, J., Luts, H., Wagener, K. C., Van Wieringen, A., Verschuure, H., et al. (2014). Development of a dutch matrix sentence test to assess speech intelligibility in noise. International Journal of Audiology, 53(10), 760-763.
International Organization for Standardization.. (2012). Acoustics—Audiometric Test Methods—Part 3: Speech Audiometry (ISO 8253-3 2012). Geneva: International Organization for Standardization.
Jain, C., Narne, V., Singh, N. K., Kumar, P., & Mekhala, M. (2014). The development of Hindi sentence test for speech recognition in noise. International Journal of Speech-Language Pathology, 2(2), 86-94.
Jang, H., Lee, J., Lim, D., Lee, K., Jeon, A., & Jung, E. (2008). Development of Korean standard sentence lists for sentence recognition tests. Audiology, 4(2), 161-177.
Johnson, K. & Mullennix, J. W. (1997). Talker Variability in Speech Processing. San Diego, CA: Academic Press.
Kalikow, D. N., Stevens, K. N., & Elliott, L. L. (1977). Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. The Journal of the Acoustical Society of America, 61(5), 1337-1351.
Kelly, H., Lin, G., Sankaran, N., Xia, J., Kalluri, S., & Carlile, S. (2017). Development and evaluation of a mixed gender, multi-talker matrix sentence test in Australian English. International Journal of Audiology, 56(2), 85-91.
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. The Journal of the Acoustical Society of America, 116(4), 2395-2405.
Kim, K. H. & Lee, J. H. (2018). Evaluation of the Korean matrix sentence test: Verification of the list equivalence and the effect of word position. Audiology and Speech Research, 14(2), 100-107.
Kim, K. H. & Lee, J. H. (2021). Influence of measurement procedure on the Korean matrix sentence-in-noise intelligibility for normalhearing listeners. Korean Journal of Otorhinolaryngology-Head and Neck Surgery, 64(1), 7-12.
King, S. E., Firszt, J. B., Reeder, R. M., Holden, L. K., & Strube, M. (2012). Evaluation of TIMIT sentence list equivalency with adult cochlear implant recipients. Journal of the American Academy of Audiology, 23(5), 313-331.
Kirk, K. I., Pisoni, D. B., & Miyamoto, R. C. (1997). Effects of stimulus variability on speech perception in listeners with hearing impairment. Journal of Speech, Language, and Hearing Research, 40(6), 1395-1405.
Kollmeier, B., Warzybok, A., Hochmuth, S., Zokoll, M. A., Uslar, V., Brand, T., et al. (2015). The multilingual matrix test: Principles, applications, and comparison across languages: A review. International Journal of Audiology, 54(suppl2), 3-16.
Kollmeier, B. & Wesselkamp, M. (1997). Development and evaluation of a German sentence test for objective and subjective speech intelligibility assessment. The Journal of the Acoustical Society of America, 102(4), 2412-2421.
Lee, J. H. & Yi, D. W. (2017). A comparison of adaptive sentence-in-noise tests. Audiology and Speech Research, 13(1), 9-18.
Mackersie, C. L. (2002). Tests of speech perception abilities. Current Opinion in Otolaryngology & Head and Neck Surgery, 10(5), 392-397.
Mullennix, J. W., Pisoni, D. B., & Martin, C. S. (1989). Some effects of talker variability on spoken word recognition. The Journal of the Acoustical Society of America, 85(1), 365-378.
Nilsson, M., Soli, S. D., & Sullivan, J. A. (1994). Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise. The Journal of the Acoustical Society of America, 95(2), 1085-1099.
Ozimek, E., Warzybok, A., & Kutzner, D. (2010). Polish sentence matrix test for speech intelligibility measurement in noise. International Journal of Audiology, 49(6), 444-454.
Pisoni, D. B. (1993). Long-term memory in speech perception: Some new findings on talker variability, speaking rate and perceptual learning. Speech Communication, 13(1-2), 109-125.
Shim, H. I. (2005). A Study of Disfluency Characteristics and Speech Rates in Normal Korean Adults (PhD dissertation). Chuncheon: Hallym University.
Sommers, M. S. (1997). Stimulus variability and spoken word recognition. II. The effects of age and hearing impairment. The Journal of the Acoustical Society of America, 101(4), 2278-2288.
Sommers, M. S. & Barcroft, J. (2006). Stimulus variability and the phonetic relevance hypothesis: Effects of variability in speaking style, fundamental frequency, and speaking rate on spoken word identification. The Journal of the Acoustical Society of America, 119(4), 2406-2416.
Sommers, M. S., Kirk, K. I., & Pisoni, D. B. (1997). Some considerations in evaluating spoken word recognition by normal-hearing, noise-masked normal-hearing, and cochlear implant listeners. I: The effects of response format. Ear and Hearing, 18(2), 89-99.
Sommers, M. S., Nygaard, L. C., & Pisoni, D. B. (1994). Stimulus variability and spoken word recognition. I. Effects of variability in speaking rate and overall amplitude. The Journal of the Acoustical Society of America, 96(3), 1314-1324.
Spahr, A. J. & Dorman, M. F. (2004). Performance of subjects fit with the Advanced Bionics CII and Nucleus 3G cochlear implant devices. Archives of Otolaryngology-Head & Neck Surgery, 130(5), 624-628.
Spahr, A. J., Dorman, M. F., Litvak, L. M., Van Wie, S., Gifford, R. H., Loizou, P. C., & et al.. (2012). Development and validation of the AzBio sentence lists. Ear and Hearing, 33(1), 112-117.
Tanniru, K., Narne, V. K., Jain, C., Konadath, S., Singh, N. K., Sreenivas, K. R., & et al.. (2017). Development of equally intelligible Telugu sentence-lists to test speech recognition in noise. International Journal of Audiology, 56(9), 664-671.
Vermeire, K., Brokx, J. P., Lemkens, N., D’Haese, P., & Van de Heyning, P. H. (2003). Speech recognition tests in sensorineural hearing loss. Acta Oto-Rhino-Laryngologica Belgica, 57(3), 169-175.
Wagener, K., Josvassen, J. L., & Ardenkjær, R. (2003). Design, optimization and evaluation of a Danish sentence test in noise: Diseño, optimización y evaluación de la prueba Danesa de frases en ruido. International Journal of Audiology, 42(1), 10-17.
Wu, Y. H., Stangl, E., Chipara, O., Hasan, S. S., Welhaven, A., & Oleson, J. (2018). Characteristics of real-world signal to noise ratios and speech listening situations of older adults with mild to moderate hearing loss. Ear and Hearing, 39(2), 293-304.
Yi, D. (2016). Study on the construction and optimization of the Korean matrix sentence materials (unpublished master’s thesis). Seoul: Hallym University of Graduate Studies.
APPENDICES
Appendix 1.
Practice and test lists (#1~15) of the 20-talker K-SIN test
Test sentence (keywords underlined)
Talker ID
# Of Keywords
Practice list
1
따뜻한 물을 자주 드세요.
m1
2
2
작은 형은경찰관입니다.
f1
2
3
매운 음식을 좋아합니다.
m2
2
4
에어컨 온도를 낮춰주세요.
f2
2
5
전화를잘못 걸었어요.
m3
2
6
월요일에 세탁소에 옷을맡겼다.
f3
3
7
내가 좋아하는 계절은가을이다.
m4
2
8
비가 와서 우산을 펼쳤다.
f4
2
9
계곡에 가서 물놀이를 했다.
m5
2
10
아이스크림을사러 가요.
f5
2
11
차가 막혀서약속 시간에 늦었다.
m6
3
12
우리는 버스를 타고 집에 왔습니다.
f6
2
13
카페에서커피를 마시며 책을 읽습니다.
m7
3
14
지하철이 끊겨서 택시를타고 왔다.
f7
3
15
당신은 짧은머리가 잘 어울려요.
m8
3
16
누나는영어를 배우기 위해 캐나다로 갔다.
f8
3
17
겨울에는감기에 걸리지 않도록 조심해야 한다.
m9
3
18
유명한드라마촬영지에 가 보고 싶습니다.
f9
3
19
배가 고프니 빨리 밥을먹으러 가자.
m10
3
20
국화를 사고 싶은데 꽃집이어디에 있나요?
f10
3
List 1
1
면허증을 만들려면 사진이 필요하다.
m1
2
2
바다가 보이는 방은 가격이 더 비싸다.
f1
3
3
두 사람은 마음이 잘 맞는 연인이다.
m2
2
4
내일 아침에 일찍 오세요.
f2
2
5
내 친구는쌍둥이다.
m3
2
6
누나는 매일 지하철을 타고 학원에 간다.
f3
3
7
서울역 앞에서 만나자.
m4
2
8
의자밑에가방을 놓으세요.
f4
3
9
언니는노란색치마를 입었다.
m5
3
10
약을 먹어서 두통이 사라졌다.
f5
2
11
종이는나무로 만들어진다.
m6
2
12
제가 좋아하는 음식은 잡채와불고기입니다.
f6
3
13
내가 사고 싶은 물건이 모두 품절되었다.
m7
2
14
엘리베이터를 타고 올라가세요.
f7
2
15
버스가출발하기 전에 안전벨트를 매세요.
m8
3
16
과제를 열심히 해서 선생님께칭찬받았다.
f8
3
17
호수에동전을 던지고 소원을 빌었다.
m9
3
18
간장과된장은 우리나라 고유의 발효 식품이다.
f9
3
19
얇은외투와 긴 바지를 챙기세요.
m10
3
20
올해 몇 살이에요?
f10
2
List 2
1
설렁탕이 뜨거우니조심하세요.
m1
2
2
오후부터눈이 내리기 시작했다.
f1
3
3
부산은해수욕장으로 유명한 도시이다.
m2
3
4
일이 많아서 정말 바쁘다.
f2
2
5
읽고 싶은 책을 모두 골라 보세요.
m3
3
6
미술전시회에 가는 길입니다.
f3
2
7
나는 학교기숙사에서 살고 있다.
m4
2
8
어머니선물로 무엇을 살지 고민이다.
f4
3
9
컴퓨터 옆에 거울이 있습니다.
m5
2
10
여름에는 해가 길다.
f5
2
11
형은 나보다 두 살 많다.
m6
3
12
다음날아침에비행기를 타고 와야 한다.
f6
3
13
건강을 위해 매일달리기를 한다.
m7
3
14
수업이끝나자마자 식당에 점심을 먹으러 갔습니다.
f7
3
15
오늘은 무슨 요일입니까?
m8
2
16
줄이 너무 길어서 기다리는 시간이 지루했다.
f8
3
17
춤을배우는 중이다.
m9
2
18
우체국에손님이 세 명 있습니다.
f9
2
19
계산은현금으로 할게요.
m10
2
20
열쇠를 어디에 두었는지기억이 나지 않는다.
f10
3
List 3
1
우리 집은기차역에서가깝다.
m1
3
2
도서관에서 열쇠를 잃어버렸다.
f1
2
3
아이가자고 있어서 조용히 이야기를 했다.
m2
3
4
부모님은초등학교 교사이다.
f2
2
5
보라색구슬이 예쁘다.
m3
2
6
그녀가 부드러운목소리로 말했다.
f3
2
7
마당에서강아지를 키웁니다.
m4
2
8
여기서 빨리나가자.
f4
2
9
편하게 앉아 있을 여유가없었다.
m5
3
10
장미꽃열 송이 주세요.
f5
2
11
내일비행기를 타고 한국으로 갈 예정이다.
m6
3
12
온 가족이거실에 모였다.
f6
2
13
주변에 공사장이 있어서 매우 시끄럽다.
m7
2
14
병원에서진료를 받고 주사를 맞았습니다.
f7
3
15
자세하게설명해 줄 수 있나요?
m8
2
16
운전기사로 오랫동안 일을 했다.
f8
3
17
배가아파서약을 먹었다.
m9
3
18
냉장고에음식을 오래 보관하지 않도록 하세요.
f9
3
19
집에 돌아오면 손을 깨끗이 씻어야 한다.
m10
3
20
올해제일 하고 싶은 일이 뭐예요?
f10
3
List 4
1
공기가 정말 깨끗하다.
m1
2
2
피아노는 언제부터 쳤어요?
f1
2
3
회색 운동복이멋지다.
m2
2
4
풍선을 많이 불어서 어지럽다.
f2
2
5
약속 시간보다 늦게 도착했다.
m3
2
6
수박이맛있어 보인다.
f3
2
7
조카의 생일 선물로자동차장난감을 샀다.
m4
4
8
동물원에 가서 코끼리와기린을 봤습니다.
f4
3
9
선착순 열 분에게 사은품을 드립니다.
m5
3
10
비행기를 타려면 공항에 가야 한다.
f5
2
11
출발하기 전에 짐을정리해야 합니다.
m6
3
12
급한 일이 생겨서 모임에참석하지 못했다.
f6
3
13
소매가 긴 옷을 입으세요.
m7
2
14
음식을 주문해서 나눠먹자.
f7
3
15
내일 잊지 말고 카메라를 꼭 가져오세요.
m8
3
16
지금퇴근하려고 하는데 무슨 일 있어요?
f8
3
17
시간이 참 빨리 간다.
m9
2
18
서울로 가는 버스는 어디에서 탑니까?
f9
2
19
시계와가방 중 무엇을 살지 고민이다.
m10
3
20
약국에서소화제를 샀어요.
f10
2
List 5
1
저는 매일자전거를 타고 출근을 합니다.
m1
3
2
나는 여름에수영장에 가는 것을 좋아한다.
f1
3
3
날씨가 제법 쌀쌀하다.
m2
2
4
추운 겨울에 먹는 호떡은 정말 맛있다.
f2
3
5
대전으로 가는 버스는 몇 시에 출발하나요?
m3
3
6
회의를 다음 주로 연기했다.
f3
2
7
오빠는 자동차정비사입니다.
m4
2
8
슈퍼에서면도기를 샀습니다.
f4
2
9
저는 혼자 있을 때 라디오를듣습니다.
m5
3
10
내일은 밖에서 외식하자.
f5
2
11
나는 술을좋아하지 않는다.
m6
2
12
날아오는축구공을 손으로 잡았다.
f6
3
13
오늘은 미세먼지가심하다.
m7
2
14
점심을 먹은 후에 박물관에 갔습니다.
f7
2
15
여기까지 오는데 얼마나걸렸어요?
m8
2
16
운동장에 가서 배드민턴을 쳤습니다.
f8
2
17
몸살이 나으려면 집에서 푹 쉬세요.
m9
3
18
신호등이 없어서 길을 건너기불편하다.
f9
3
19
비가 와서 야구 경기가 취소되었다.
m10
3
20
침대 위에 안경과휴대폰이 있어요.
f10
3
List 6
1
오늘은 창가자리가 다 찼습니다.
m1
3
2
비가 많이 오는 날에는 조심해서운전하세요.
f1
3
3
야경이 정말 아름답다.
m2
2
4
건강을 위해 과식하지 말고 운동을 하세요.
f2
3
5
학원에서빵을 만드는 기술을 배우고 있습니다.
m3
3
6
엄마와 함께 벚꽃구경을 다녀올 거예요.
f3
3
7
저는 오늘 새 집으로 이사를 왔습니다.
m4
2
8
시험 문제가 어려웠다.
f4
2
9
시간이 없으니 택시를 타자.
m5
2
10
계란은어디에 있어요?
f5
2
11
약을하루에세 번 드세요.
m6
3
12
날씨가 흐려서 쌀쌀하다.
f6
2
13
오빠는 나보다 키가크다.
m7
3
14
여자가 신문을 보면서 차를마셔요.
f7
3
15
다음 신호등에서내려주세요.
m8
2
16
내일전화로 문의해 주세요.
f8
2
17
가장 가까운경찰서는 어디입니까?
m9
2
18
귀여운 강아지가이불속에 있다.
f9
3
19
수영복이 없어서 바다에들어가지 못했다.
m10
3
20
어릴 적에 부산에 살았다.
f10
2
List 7
1
오랜만에친구들을 만나서 수다를 떨었다.
m1
3
2
저는 오렌지주스를 제일 좋아합니다.
f1
3
3
주차장이 꽉 찼다.
m2
2
4
자기 전에 샤워하고머리를 말려요.
f2
3
5
신청서를작성한 후에 직원에게 주세요.
m3
3
6
기분이 안 좋을 때는 노래를듣는다.
f3
3
7
교실에서 학생들은 흰색실내화를 신어야 한다.
m4
3
8
얼마 전에 산 휴대폰을물에빠뜨렸다.
f4
3
9
음식을 먹고 계산을 하려는데 지갑이 없었다.
m5
3
10
방에서 큰 소리가 나서 깜짝 놀랐다.
f5
3
11
목이 말라서 냉장고를 열었다.
m6
2
12
휴가는 어디로 가세요?
f6
2
13
예약이 많아서 오래 기다리셔야 됩니다.
m7
2
14
교통카드를 사용하면 편리합니다.
f7
2
15
비가 오니 우산을 챙겨라.
m8
2
16
컴퓨터를 언제 샀어요?
f8
2
17
텔레비전 옆에 화분이 있습니다.
m9
2
18
모자 색이 예쁘다.
f9
2
19
야채를씻은 후에 썰어주세요.
m10
3
20
내일은 중요한 면접이 있습니다.
f10
2
List 8
1
깜빡잠이 들었다.
m1
2
2
도서관에서 처음 책을빌렸어요.
f1
3
3
나는 운전을잘 한다.
m2
2
4
식사는규칙적으로 하는 것이 좋다.
f2
2
5
여행할 때는 편안한신발을 신으세요.
m3
2
6
지하철 안에서 초등학교동창을 만났다.
f3
3
7
공연이시작하기 전에 화장실을 다녀오세요.
m4
3
8
남산 근처에 맛있는냉면 집이 있다.
f4
3
9
이번 여행을 통해 특별한추억을 쌓았다.
m5
3
10
내일오전에배를 탈 수 있을까요?
f5
3
11
내 동생은 엄마보다 아빠를 더 닮았다.
m6
3
12
너무 피곤해서주말에 집에서 휴식을 취했다.
f6
3
13
공원에서음료수와과자를 먹었다.
m7
3
14
택시를 타고 결혼식에 갔다.
f7
2
15
호텔 직원이 친절하다.
m8
2
16
눈이 오면 아이들은눈사람을 만들어요.
f8
2
17
마트에서 우유를샀습니다.
m9
2
18
어떤 소설을좋아하세요?
f9
2
19
커피한 잔 주세요.
m10
3
20
우리 아버지는회사원입니다.
f10
2
List 9
1
선물받은목걸이가 마음에 든다.
m1
2
2
축제는평일오후에 개최된다.
f1
3
3
오늘은 추워서두꺼운외투를 입고 나왔다.
m2
3
4
고등어 세 마리 주세요.
f2
3
5
최근에 새로운 자동차 기술이 개발되었다.
m3
2
6
이번에 도착한 숙소는 방이 넓고깨끗했다.
f3
3
7
유명한 관광지에는 항상 사람이많다.
m4
3
8
이번 주말에사촌 형이 결혼한다.
f4
3
9
당신은 파란색 옷이 잘 어울려요.
m5
2
10
우리 집 강아지는산책하는 것을 좋아한다.
f5
3
11
제품을사용하기 전에 설명서를 읽어 보세요.
m6
3
12
신분증을보여 주세요.
f6
2
13
아이가 몇 학년입니까?
m7
2
14
음식을 먹을 만큼 그릇에담으세요.
f7
3
15
싱거우면소금을 더 넣으세요.
m8
2
16
아버지는힘이 세다.
f8
2
17
나이가어떻게 되세요?
m9
2
18
다시 만나서반갑습니다.
f9
2
19
밥을급하게 먹으면 체할 수 있어요.
m10
3
20
가만히 눈을감아 보세요.
f10
2
List 10
1
마음에 드는 구두를 한 번 신어보세요.
m1
3
2
오른쪽으로 가면 됩니다.
f1
2
3
남는우산 있으세요?
m2
2
4
평일에는카페에서 일을 합니다.
f2
2
5
친구들을모임에초대하고 싶습니다.
m3
3
6
서점 앞에서 만나요.
f3
2
7
시골에별장을 짓기로 결정했다.
m4
3
8
아침에 일어나면 꽃에물을 줍니다.
f4
3
9
방학 계획을 세웠다.
m5
2
10
문구점에서공책과연필을 샀어요.
f5
3
11
밥을조금만 더 주세요.
m6
2
12
잡채 만들 때 무슨 재료가필요해요?
f6
3
13
거기 있는 신문 좀 주세요.
m7
2
14
기타를 잘 치려면 꾸준히연습해야 한다.
f7
3
15
일을 끝내고 서둘러 약속 장소로 출발했다.
m8
3
16
아이들은주사 맞는 것을 싫어한다.
f8
3
17
날이 추우니 옷을따뜻하게 입어라.
m9
2
18
토요일에는 식당 문을 일찍 닫는다.
f9
2
19
안내 책자를읽으세요.
m10
2
20
창고에 낡은 의자가세 개 있었다.
f10
3
List 11
1
당신의 직업은무엇인가요?
m1
2
2
길에서친구를 만났다.
f1
2
3
후식으로과일을 먹어요.
m2
2
4
날씨가 매우 덥다.
f2
2
5
카메라 좀 빌려 줄 수 있어요?
m3
2
6
저는 치마를사고 싶어요.
f3
2
7
매년치과에서검진을 받는다.
m4
3
8
도서관에서는조용히 해야 한다.
f4
2
9
짐을 좀 옮겨 주세요.
m5
2
10
국수를 담기에는 그릇의 크기가 작다.
f5
3
11
어릴적꿈은과학자가 되는 것이었다.
m6
3
12
정원에 나무와꽃이 많아서 참 아름답습니다.
f6
3
13
시험에합격하기 위해 늦게까지 열심히 공부했다.
m7
3
14
도착하기 전에 미리전화해 주세요.
f7
3
15
음식을준비 중이니 잠시만 기다려주세요.
m8
3
16
비행기 표를 예약한 후에 숙소를 알아봤다.
f8
3
17
나는 전철과마을버스를 자주 이용한다.
m9
3
18
비가 오면 영화를 보러 극장에 갑니다.
f9
3
19
눈이 나빠져서 안경을맞췄다.
m10
2
20
어제 누구를만났어요?
f10
2
List 12
1
날이 더우니시원한냉면이 먹고 싶다.
m1
3
2
인천으로 가는 버스가 막 출발했다.
f1
3
3
모든 고객에게손수건을선물로 드립니다.
m2
3
4
박물관에 가기 위해 지하철을 타야 합니다.
f2
2
5
회의는 몇 시에 시작하나요?
m3
2
6
오늘은집에일찍 가야 해요.
f3
3
7
축구장에 많은 사람들이 응원을 하러 왔다.
m4
2
8
더 궁금한 것이 있으면 이메일을보내세요.
f4
3
9
출장 잘 다녀오세요.
m5
2
10
저는 서울에서태어났습니다.
f5
2
11
일요일 아침에 교회에 갑니다.
m6
2
12
수업이 끝난 후에 불을 끄고 나갔다.
f6
3
13
직장 때문에 작년에부산으로 이사했다.
m7
3
14
누구하고 같이 왔어요?
f7
2
15
무슨음식을 좋아하세요?
m8
2
16
시청옆에소방서가 있습니다.
f8
3
17
기다리던 영화가 곧 개봉한다.
m9
2
18
주말에는차가 많이 막힌다.
f9
3
19
따끈한만두 주세요.
m10
2
20
마을앞에 큰 강이 흐른다.
f10
3
List 13
1
공부하러독서실에 갑니다.
m1
2
2
이십 분 간격으로버스가 다닌다.
f1
3
3
월요일과수요일 중에 언제가 좋으십니까?
m2
2
4
바다에서수영을 했어요.
f2
2
5
우체국에 가는 길에 편의점에 들를 거예요.
m3
2
6
이번 달은 전기요금이 꽤 줄었다.
f3
3
7
가족과스키장에 갔습니다.
m4
2
8
안경을 쓴 사람이 우리아버지다.
f4
3
9
양배추와당근을 깨끗이 씻으세요.
m5
3
10
음식 좀 나눠 드릴까요?
f5
2
11
선물을 받으려면 행사장으로 가야 한다.
m6
2
12
봄에는꽃이 많이 핀다.
f6
3
13
새로운 간식을만들어보자.
m7
2
14
복도 끝에서 왼쪽으로 가세요.
f7
2
15
몸이 약해서감기에 자주 걸린다.
m8
3
16
하늘을 보니 비가올 것 같다.
f8
3
17
영화가 시작하기 전에 팝콘과음료수를 샀다.
m9
3
18
내 동생은 농구 선수처럼 키가크다.
f9
3
19
두꺼운옷과우산을 준비하세요.
m10
3
20
언니는 성격이 외향적이다.
f10
2
List 14
1
엄마가아이에게책을 읽어주고 있다.
m1
3
2
창문을 열자 시원한 바람이들어왔다.
f1
3
3
병원에 가려면 시내로 나가야 한다.
m2
2
4
시간이 없어서 빵하고우유를 먹었어요.
f2
3
5
가족이 몇 명이에요?
m3
2
6
새벽에눈이 많이 내려서 길이 미끄럽다.
f3
3
7
아침에우체국에 가서 택배를 보내야 한다.
m4
3
8
참석 인원이 갑자기 늘어서 좌석이 부족하다.
f4
3
9
감자와양파를 넣고 약한 불로 볶아주세요.
m5
3
10
친구에게 줄 선물을포장했다.
f5
3
11
나는식혜를 좋아한다.
m6
2
12
지금 일자리를구하고 있어요.
f6
2
13
입장하려면 얼마나 기다려야 하나요?
m7
2
14
메모를남겨 주세요.
f7
2
15
재료를창고로 옮기세요.
m8
2
16
오늘은산책하기 좋은 날이다.
f8
2
17
며칠 전에 감기에걸렸어요.
m9
2
18
청소기가 계속 고장이 나서 수리를 맡겼다.
f9
3
19
일은 힘들지만재미있어요.
m10
2
20
골목에고양이다섯 마리가 있었습니다.
f10
3
List 15
1
작년까지 은행에서근무했다.
m1
2
2
사진 찍는 기술은 계속 발전하고 있다.
f1
3
3
출근할 때 길이 너무 막혀서불편하다.
m2
3
4
저는 어릴 때부터 춤추는 것을 좋아했습니다.
f2
3
5
최근에 본 영화가 정말 인상 깊었다.
m3
2
6
그는 성격이활발하다.
f3
2
7
신발이예뻐서두 켤레나 샀습니다.
m4
3
8
매주 수요일 오후에 시장에 갑니다.
f4
2
9
출입문오른쪽에화장실이 있어요.
m5
3
10
추석에이웃들과송편을 만들어요.
f5
3
11
오늘은 백화점휴일이다.
m6
2
12
유리창을 깨끗이 닦았다.
f6
2
13
당신의 혈액형은무엇입니까?
m7
2
14
비는 오늘 밤에 그칠 예정이다.
f7
2
15
맛있는음식을 만들어 먹는 것은 즐겁다.
m8
3
16
교통비를 절약하려고 자전거로 출근해요.
f8
2
17
시험에통과해서기분이 좋습니다.
m9
3
18
휴일에는놀이공원에 사람이 많아요.
f9
3
19
선물받은 옷이커서교환해야 한다.
m10
3
20
사람들이 많아지면서 거리가 더 복잡해졌습니다.
f10
2
20-talker K-SIN test: 20-talker Korean Sentence In Noise test, ID: identification