INTRODUCTION
When portions of speech signals are distorted due to atypical pronunciation (e.g., foreign accent) or degraded by the presence of background noise, listeners’ ability to processing acousticphonetic information (bottom-up processing) is compromised. In such a situation, listeners attempt to compensate by tracking the concept expressed in the message (top-down processing) to aid word recognition (Nittrouer & Boothroyd, 1990). Although models of speech perception differ in terms of how top-down and bottom-up processing skills work in combination, there seems to be agreement that bottom-up processing is automatic and essential for good speech perception. In contrast, top-down processing can be more effortful and is influenced by the integrity of bottom-up processing (Marslen-Wilson & Warren, 1994; Massaro, 1989; McClelland et al., 2006; Norris et al., 2000). Thus, the overuse of top-down processing to compensate for suffering bottom-up processing may impede overall efficiency of speech perception. As a part of a larger project investigating speech perception in challenging listening conditions (in noise, hereafter) for various populations, the present study evaluated the feasibility of a novel method of classifying listening strategies of individuals based on their relative use of bottom-up and top-down processing.
Second-language learners were chosen as the target population for their documented difficulty with speech perception in noise (Garcia Lecumberri et al., 2010). In general, studies comparing native and second-language learners suggested that normal hearing and native-like phonological awareness are fundamental for good speech perception in noise (Garcia Lecumberri et al., 2010; Mattys et al., 2012). In other words, perceptual problem that second-language learners experience in noise can be considered primarily due to acoustic-phonetic interference from their native language worsened by masking from noise, which in turn have cumulative detrimental impact on higher-level processes, such as syntax, semantics, and pragmatics. (Bradlow & Alexander, 2007; Cutler et al., 2004; Garcia Lecumberri et al., 2010; Mayo et al., 1997; Rogers et al., 2006).
Bradlow & Alexander (2007) showed that second-language learners can benefit from contextual information only when a sentence is spoken in a clear-speech style, underscoring the importance of accurate bottom-up processing for second-language learners. However, even highly proficient second-language learners may not be able to completely suppress the interference from the native language (Weber & Cutler, 2006), which can account for their compromised speech perception in noise performance despite native-like performance in quiet (Mayo et al., 1997; Rogers et al., 2006).
Still, in spite of the risk of compromising overall efficiency, the common strategy for second-language learners is to rely on contextual information to compensate for shortcomings in bottom-up processing. In fact, although the need for such compensatory use of top-down processing reduces with proficiency (Meador et al., 2000; Tsui & Fullilove, 1998), second-language learners tend to use more top-down processing than native speakers (Tyler, 2001).
The goal of the present study was to validate the use of novel method of identifying individuals who use atypical listening strategies with a listener group whose speech perception in noise performance has been relatively well-documented.
MATERIALS AND METHODS
Participants
Forty-seven adult Spanish-speaking, second-language learners of English (L2; mean age = 30.5 years old, range = 19-57 years; 38 female, 9 male) and 60 adult monolingual speakers of American English (AE; mean age = 27.3 years old, range = 19-50 years; 41 female, 19 male) participated as listeners. All but nine (3 AE and 6 L2) had pure-tone thresholds ≤ 20 dB HL bilaterally at octave frequencies from 250 Hz to 8,000 Hz. The nine listeners had single-sided elevated thresholds (25-30 dB HL) at one of the frequencies.
The L2 listeners were fluent in English but represented a broad range of linguistic history and usage characteristics (Table 1). Briefly, the onset of learning English varied from infancy to 45 years old. Although Spanish was the comfortable language for the majority to speak (n = 30) and read (n = 25), 28 L2 listeners spoke both English and Spanish at home, but none reported to speak only Spanish at work or school.
L2 listeners were also screened for articulation errors in English with Bankson-Bernthal Quick Screen of Phonology (BBQSP) (Bankson & Bernthal, 1990). Consistent error patterns (e.g., /b/ for /v/) noted with BBQSP were used to guide scoring during the listening task. Listeners with random articulatory errors were excluded from further testing. Language background questions (current age, age of arrival in the U.S., onset age of learning English, language use, preferred language for reading/writing and speaking; see Appendix for actual questions) were administered orally. L2 listeners who could not understand/answer these questions were considered not fluent in English and were not tested further. Finally, L2 listeners who scored below 80% on speech recognition in quiet were also excluded (see Stimuli section for speech materials used for this). Additional 35 L2 listeners were recruited, but they were excluded due to heavy accent that interfered scoring, poor speech recognition in quiet, low proficiency in English, hearing loss, or voluntary withdrawal.
Stimuli
Words from the Phonetically Balanced Kindergarten (PBK) Test (Haskins, 1949) and sentences from the Bamford-Kowal-Bench (BKB) Standard Sentence Test (Bench & Bamford, 1979) were used as stimuli. They met two requirements: 1) meaningful yet simple for all listeners, thus minimizing memory load and minor grammatical errors; 2) minimal learning effects between the two materials.
The PBK Test is a word recognition test consisting of four lists of 50 monosyllabic words that are phonetically balanced and familiar to kindergarten-age children. In particular, lists 1, 3, and 4 were found to be equally effective as materials for adults (Harvard PB-50 test) (Egan, 1948; Haskins, 1949). These lists have been used extensively for more than 50 years for clinical assessment of speech perception for children between 6 and 12 years old. The present study used words from lists 1, 3, and 4 (150 words) for the listening task. BKB Test consists of simple everyday sentences that were originally developed in Britain and were subsequently modified for use in the U.S. to evaluate speech perception in noise for children between 5 and 15 years old. All 320 sentences are syntactically and semantically appropriate and contain three to four keywords each. Only 26 words were shared between PBK words and BKB sentences. Although nonsense words would allow more effective examination of acoustic-phonetic cue processing, nonsense materials were avoided to minimize the influence of unnatural phonotactics, unintended similarity to Spanish words, and confusion with real words, which were expected to have greater influence on second-language learners. For assessing L2 listeners’ performance in quiet, 25 PBK words (half of List 4) and 20 BKB sentences (List 1A & B) that were not test stimuli were used.
Procedure
After consenting, hearing screening and speech and language tests described above were administered to individual participants. A brief language background questionnaire was verbally administered to the L2 listeners. L2 listeners were also screened with 25 PBK words and 20 BKB sentences that were not test stimuli to ensure good performance in quiet. The cutoff score (80%) for both words and sentences was chosen in reference to the critical differences from 95%-correct (1 error) recognition on 25-item speech tests (Raffin & Thornton, 1980).
All speech stimuli were presented to individual listeners in a sound-attenuated booth. Both in the experimental and the inquiet tasks, listeners repeated the speech stimuli exactly as heard, even if they did not make sense. However, listeners were told that all speech stimuli were meaningful. Responses were scored online by an experimenter. PBK words were scored as correct only when the entire word was correct. BKB sentences were scored as correct only when all keywords in a sentence were repeated in correct order. In the case of unclear/ambiguous responses, the intended answer was confirmed by asking to spell or define words or by asking for clarification using the results of BBQSP (e.g., for /f/-/θ/ confusions, “Did you mean /f/ as in ‘off’ or /θ/ as in ‘bath’?”) for some L2 listeners who were not proficient spellers.
Stimuli were presented binaurally via earphones (Sennheiser HD25; Sennheiser, Wedemark, Germany) in a background of speech-shaped noise (ANSI S3.5-1997) (American National Standards Institute, 1997) at a fixed overall rms level of 65 dB SPL. Speech-shaped noise was used as background noise to avoid possible interaction between language of babble and signal for L2 listeners because multi-talker babble in native language masks speech more effectively than the non-native babble (Van Engen & Bradlow, 2007). Stimulus presentation and response acquisition were controlled by Behavioral Auditory Research Tests, a computer program developed at Boys Town National Research Hospital. Presentation order between PBK words and BKB sentences was randomized across listeners. Listener performance was measured as the signal-to-noise ratios for 70%-correct performance (SNR70) using adaptive-tracking method (Levitt, 1971). Specifically, each block started at 10 dB SNR; noise level was increased following two correct responses and decreased following each incorrect response to estimate SNR70; following the first four reversals, step size was decreased from 4 dB to 2 dB. Tracking stopped after four reversals at the smallest step size. The SNR70 was calculated as the mean value of all reversals obtained with the smaller step size. The total number of trials for each listener varied depending on how rapidly the criterion was met for 70%-correct performance. This procedure was repeated six times-three for PBK words and three for BKB sentencesand average SNR70 values were calculated for each listener across three blocks for PBK words and BKB sentences. The three blocks were presented in a random order. The software chose the items for each trial in a random manner. The entire testing time to obtain SNR70 for both materials was less than 30 minutes per listener.
RESULTS
Visual inspection of data indicated that SNR70 values for words and sentences for the nine listeners with slightly elevated pure-tone thresholds at a frequency in one ear did not differ from other listeners. Therefore, results from these listeners were included in their respective groups in all analyses.
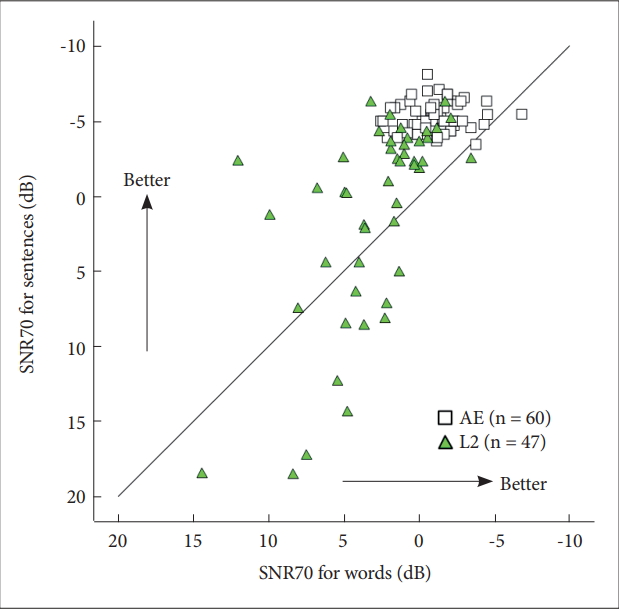
Figure 1 presents the word and sentence SNR70 values for the AE (open square) and L2 (green triangle) groups. A data point above the diagonal line indicates that SNR70 was lower (better performance) for sentences than for words-i.e., benefit of context in sentence.
As can be seen, while AE listeners formed a tight cluster with slightly greater variance for word SNR70 than for sentence SNR70, L2 listeners SNR70 distributed broadly especially for sentence SNR70. For the majority of listeners, SNR70 was lower for sentences than for words, suggesting the benefit of context. Another point to note is that some L2 listeners’ SNR70 values for both sentences and words were similar to those for the AE listeners.
The above observations were statistically evaluated. First, Levine’s test of homogeneity of variance was performed. Results suggested that within-group variances for AE and L2 groups significantly differed from each other for both PBK words [F(1, 105) = 16.26, p < 0.001] and BKB sentences [F(1, 105) = 75.94, p < 0.001]. This precludes comparing groups using statistical methods sensitive to variance difference across groups, such as analysis of variance. Therefore, linear discriminant analysis (LDA) (c.f., Klecka, 1980) was used in the subsequent analyses to quantify group differences and to evaluate individual listeners’ group membership.
LDA is a multidimensional correlational technique that allows quantification of differences among two or more groups using multiple measurements simultaneously. Using centers of gravity and within-group dispersion for each group in the input dataset, it computes weighted parameter values (discriminant functions) that maximize the distance between groups. It then applies the data-driven group parameter weights to all data points and calculates their probability of membership to each of the pre-specified groups.
First, to evaluate the independent contribution of word and sentence SNR70 for the membership classification of AE and L2 listeners in LDA, SNR70 values for sentence and words were entered in a manner similar to stepwise regression analysis. Results showed that both word and sentence SNR70 values contributed significantly [Wilks’ Lambda = 0.59, F(2, 104) = 36.60, p < 0.001]. Therefore, both sentence and word SNR70 values were entered in the subsequent analyses.
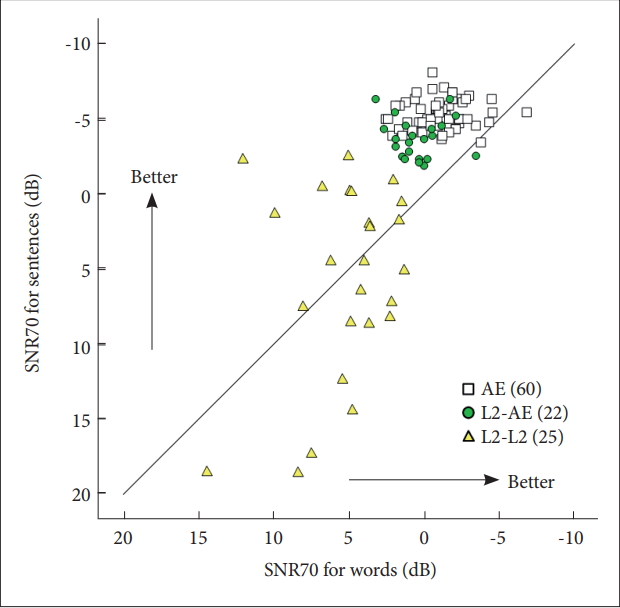
The results of membership classification are shown in Figure 2. Despite all L2 listeners’ near-optimal performance in quiet, acoustic-phonetic cue processing (word SNR70) and the use of context (sentence SNR70) in noise were native-like only for approximately half of the L2 listeners (n = 22; L2-AE hereafter); the other half (n = 25; L2-L2 hereafter) required more favorable SNR70 values to achieve a similar level of performance to native speakers and L2-AE listeners. Variability among the L2-L2 listeners was greater for sentence SNR70 (21.11 dB) than for word SNR70 (13.11 dB), illustrating greater individual differences in top-down processing.
Notice that 12 L2-L2 listeners could tolerate higher levels of noise for sentences than for words (above the diagonal line), suggesting that, similar to native speakers and L2-AE listeners, context in sentences facilitated their performance. In contrast, the remaining 12 L2-L2 listeners could not benefit from context. To evaluate whether these listeners differed in language experience and/or speech perception in quiet performance, the 12 L2-L2 listeners who benefit from context (L2-L2a), and the 12 L2-L2 listeners who did not (L2-L2b) were compared. Table 2 presents the summary along with those for L2-AE listeners for reference. One L2-L2 listener whose SNR70 values were equivalent (1.67 dB) is not included.
As can be seen in Table 2, L2-AE listeners started to learn English at a younger age and had more years of experience with English than either L2-L2 groups. Interestingly, however, no striking difference was noted between the two L2-L2 groups except for their sentence recognition in quiet.
DISCUSSIONS
The present study was designed to determine whether a new method that characterizes the relative use of bottom-up and top-down processing can be a tool to illustrate causes of speech perception difficulty experienced by second-language learners. With Spanish-speaking second-language learners who were proficient in English, the SNR70 were obtained on simple words and sentences commonly used in clinical testing with children.
When SNR70 values for these L2 listeners were evaluated against those of native speakers via linear discriminant analyses, approximately half of the L2 listeners were classified as “native-like.” Specifically, similar to the native listeners, these listeners’ SNR70 values were lower for sentences than for words, suggesting that the sentence context allowed them to fill in the portions of speech signal masked by noise. In contrast, the remaining half of the L2 listeners required more favorable SNR than native listeners to achieve 70% accuracy. For a half of the “non-native” L2 listeners, similar to the “native-like” L2 listeners, SNR70 was lower for sentences than words, suggesting that they too could tolerate higher background noise level due to the benefit of context in sentences. In contrast, the remaining half of the “non-native” L2 listeners showed the opposite pattern and required higher SNR70 for sentences than for words, indicating that they could not use sentence context effectively. When these “non-native” L2 listeners were compared in terms of commonly assessed language experience measures (age of arrival, years of residence in the U.S., onset age of learning English, and years of learning), no striking difference was found. The “native-like” L2 listeners’ onset age of learning was younger and with more years of experience than “non-native” L2 listeners.
The results of the present study show that the method used in the present study successfully captured differences between native and L2 listeners, as well as among L2 listeners. The difference captured were both related and unrelated to the language background of the L2 listeners. That is, for the L2 listeners whose SNR70 were native-like, the well-documented “earlier and longer the better” principle with second language learning held true. The present results also showed that despite similar experience (i.e., onset age of learning, years of learning, years of residence, age of arrival), not all second-language learners use the same strategy to perceive speech in noise.
Finding that the onset age of acquisition positively correlates with second-language speech perception in noise performance,Shi (2010) emphasized that language background should be considered when understanding second-language listeners’ speech perception in noise performance. For this purpose, a language questionnaire would be a useful tool that can be administered in the waiting room outside the appointment time and allows clinicians to determine whether testing using English speech materials is appropriate for a non-native client. However, as the present results for the “non-native” L2 listeners show, language background questionnaire may not capture individual differences in listening strategies (i.e., reliance on/effective use of top-down/bottom-up processing). The method used in the present study may be useful in identifying the shortcomings in listening strategies individual listeners use. Such information can possibly serve as a guide to provide explicit instructions/exercises to modify listening strategies to alleviate difficulty listeners experience in challenging listening conditions and improve learning/consulting outcomes for second-language learners who suffer atypical susceptibility to background noise.
Although promising, the proposed method requires further investigation before being put in to use as a teaching/clinical tool. First, the present results may be specific to a population. Some of the populations to be looked into are second-language learners with different first language, listeners with hearing loss, individuals with speech and language issues, and children. The method employed in the present study may be useful only with normal-hearing adult second-language learners who are highly proficient. It would be of both theoretical and clinical interest to test the present method with different populations.
Second, stimuli used here may not reflect listening activities in real life. When more complex materials are used, all non-native listeners may perform more poorly. It is also known that the detrimental effects of reverberation and noise are greater than their independent effects (Neuman et al., 2010), no distortion other than speech-shaped noise was used in the present study. Speech-shaped noise was used as background noise to avoid possible interaction between language of babble and signal for L2 listeners. However, considering that multi-talker babble in native language masks speech more effectively than the non-native babble (Van Engen & Bradlow, 2007), when speech maskers are used, different results may be observed for different populations. Using more realistically-challenging listening conditions and speech materials with varied complexity would increase the validity and generalizability of the present findings.
To address some of these limitations, a study with Englishspeaking children who are suspected for auditory processing disorder is on the way.